Submissions and Evaluation
Submissions
Phase 1: Upload output file for model targeting all 6 countries! Submission link can be accessed after you log in. The task is described in the Overview section. The submission file is required to follow the following guidelines: For each image in the test dataset, your algorithm needs to predict a list of labels, and the corresponding bounding boxes. The sample submission file may be accessed here. The output is expected to contain the following two columns:
- ImageId: the id of the test image, for example, "India_00001.jpg".
- PredictionString: the prediction string should be space-delimited of 5 integers. For example, 2 240 170 260 240 means it's label 2, with a bounding box of coordinates (x_min, y_min, x_max, y_max). We accept up to 5 predictions. For example, if you submit 3 42 24 170 186 1 292 28 430 198 4 168 24 292 190 5 299 238 443 374 2 160 195 294 357 6 1 224 135 356 which contains 6 bounding boxes, we will only take the first 5 into consideration.
Phase 2: Format (may be updated): Following files need to be submitted:
- Saved model file (.pt or any other format),
- Inference_Script.py – that loads the model and perform inference on test images generating .csv files (same as Phase 1) as output,
- Test data is provided as an argument to the Inference_Script.py.
- Test_data: {India, Japan, Norway, United States, 6_Countries}
- The inference speed achieved for Test_data: {6_Countries} decided the leaderboard ranking. The other cases will be used for special awards.
- requirement.txt (to install the requirements for running the submitted Inference_Script). Use this form to provide the details of libraries required to run your model (to be pre-installed in the Organizers' side system), if required.
Feedback Invitation and Model Evaluation Process for Phase 2
To ensure transparency and clarity in the evaluation process for your submitted models, the corresponding procedure is outlined below. Currently, the final ranking is based on inference speed. However, this criterion may be adjusted to include F1-score based on feedback and the quality of submissions received. Expert feedback is sought to ensure that the evaluation criteria effectively capture model performance and to consider any necessary refinements.
- Instance Specification: The inference time of the submitted model is measured using an AWS EC2 instance of type "g4dn.xlarge".
- Execution of Inference Script: The submitted inference script will be executed in subprocess module of Python.
- Evaluation Scope: The inference script is executed for these countries:
- India
- Japan
- Norway
- United States
- Overall 6 countries
- Consistency Check: To account for the variation in system measurement, the inference process will be repeated three times for each country. The average inference time from these runs will be used for evaluation.
- Inference Speed Calculation: For each country: Inference Speed = (Inference_Time) / (Number_of_Test_Images)
- Estimated Time: Evaluations with the sample script and a sample lightweight model take approximately 60 minutes. Please anticipate longer processing times for larger models.
- Feedback Form: Your expertise is key to driving collective innovation in this challenge. We invite you to provide valuable feedback on our evaluation criteria to help refine and enhance our process. Exceptional feedback could lead to an exclusive invitation to co-author the final paper with the organizers, summarizing the challenge and its insights. Your input will directly impact the success and fairness of the evaluation process.
- Ensemble Learning (Update: Aug 26, 2024) The submission site now accommodates ensemble learning and multiple model uploads. Nevertheless, we continue to prioritize faster, lightweight models (preferably single models) with an F1-Score of at least 70%.
Phase 3: Report and Source Code submission All the participants need to submit a detailed report and source code for their proposed model. The submitted report will serve as main criteria for the following:
- Finalizing the winners of the competition.
- Those who have top scores in the leaderboard but do not submit the detailed report will be disqualified from the competition.
- Invitation to submit papers.
- Generally, the top 10 participants are invited, but based on the content of the submitted report, up to 20 participants may be considered.
- Invitation for collaboration with organizers for the paper writing.
- Based on the report content, selected teams will be invited to write a joint paper coauthored with the challenge organizers.
- Report and Source Code upload -- https://forms.gle/XXpgoPeX82Tm4HRS6
- Information for Models Trained -- https://forms.gle/zua7cNn1UgQrQifR7
- Feedback -- https://forms.gle/CBh3dmMFWJP83tN19
Paper submission
- After the competition phase is completed, a link for submitting the accompanying academic paper will be provided to the top 10 participants the number may change based on quality of submissions) as ranked by the leaderboard described above.
- Peer reviewers will review the academic papers.
- The papers are expected to conform to the format set by the conference, which can be found at IEEE BigData CFP.
Contents in the technical paper and report (Required):
- Explanation of your method and the tools used.
- Evaluation of your method (you can use results obtained on the site of road damage detection challenge)
- Detailed evaluation of your results based on factors like inference speed, model size, training time etc.
- Code and trained model links.
- Error Analysis: Examples of failed attempts, efforts that did not go well.
Your Code
Source code will also be required to be submitted, through a publicly available repository on a Git-based version control hosting service such as GitHub for the final evaluation. All source codes are expected to be released as open-source software, utilizing some generally accepted licensing such as Apache License 2.0, GNU General Public License, MIT license, or others of similar acceptance by the Open-Source Initiative.Evaluation
Abstract: Participants will be evaluated at the following three stages:
- Phase 1: Qualifying round: Teams with an F1-score greater than 70% qualify for the top 3 positions in the competition.
- Phase 2: Ranking Round: Teams ranked according to the inference speed of their models (F1-score > 70% is the qualifying criteria for top 3 poistions).
- Phase 3: Evaluation of the submitted Report and Source Code.
Details:
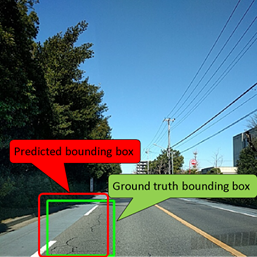
Phase 1: The results of the model proposed by the participants are evaluated by "F-Measure." The prediction is correct only when IoU (Intersection over Union, see Fig.1) is 0.5 or more, and the predicted label and the ground truth label match. Dividing the area of overlap by the area of the union yields intersection over union (Fig.2).
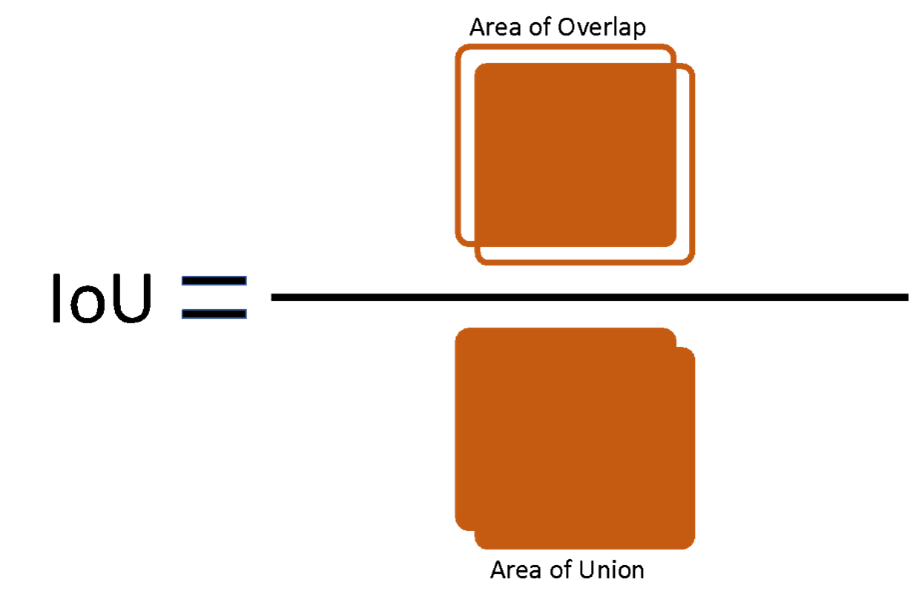
Phase 2: Inference Speed of the models proposed by the participants would be the primary evaluation criteria. Participants need to submit their proposed model file (saved checkpoint, .pb file or some other format), along with the inference script (.py file) and corresponding information of implementation requirements (.txt). Update (17/08/2024): In case of two teams having large difference between one metric (F1-score and Inference Speed) and comparable performance for other one, the rank will be decided based on the submitted report and reviewers comments.
Phase 3: Subjective evaluation of the submitted Report and Source Code will be carried out to finalize the winners of the competition. Also, based on the report content, selected teams will be invited to collaborate with the organizers for paper writing.